Performance
This document presents benchmark results and performance analysis for the current implementation.
Methodology
Benchmark harness
The benchmark is driven by the Criterion.rs library
(crates/ahdapa-bench/) and orchestrated by contrib/bench/bench.sh.
What each run measures:
| Scenario | What it tests |
|---|---|
client_credentials | One token endpoint round-trip per supported auth method |
auth_code | Full authorization code + PKCE flow: login → /authorize → /token (3 round-trips) |
introspect | Token introspection of a pre-minted token |
| gossip convergence | Time for a key-value write on node 0 to appear on all other nodes |
Criterion collects 100 samples per benchmark function (warm-up: 3 s,
measurement window: 30 s). The 30 s window gives adequate headroom for
slower post-quantum algorithms (ML-DSA-87 JWT signatures) without the
Unable to complete 100 samples warning that the default 5 s window triggers.
The reported value is the mean of those 100 samples. Confidence
intervals span the 5th–95th percentile of Criterion’s bootstrap estimation.
Memory overhead (live heap Δ, peak heap, and total allocation pressure) is
printed alongside latency but not analysed here.
Grid dimensions:
- 7 algorithms:
ES256,ES384,ES512,EdDSA,ML-DSA-44,ML-DSA-65,ML-DSA-87 - 6 node counts: 1, 2, 3, 5, 7, 10
- 42 runs total; each run takes approximately 7 minutes (30 s Criterion measurement window per benchmark group)
Measurement environment:
- Host: Fedora 42 (x86-64, Linux 6.15)
- Build:
cargo bench --release(benchprofile with--releaseflag) - Ahdapa server:
releaseprofile; both the Criterion harness and the Ahdapa nodes are compiled with full optimisations - TLS: loopback HTTPS with a per-run self-signed P-256 CA; no OCSP or CRL
- Rate limiting: disabled (
auth_rate_limit = 0) - Criterion request routing: round-robin across all cluster nodes via a shared
Arc<AtomicUsize>counter - Git commit:
e207adaf(audit-journald branch)
Topology:
| Nodes | Topology | Description |
|---|---|---|
| 1–5 | full-mesh | Every node peers with every other node |
| 6–10 | hub-spoke | Node 0 (hub) peers all; others peer only to hub |
Gossip interval is 2 seconds in both topologies. The gossip loop wakes
immediately on CRDT writes via tokio::sync::Notify; the interval is a
fallback for passive re-sync only.
Auth code node affinity
All three steps of the authorization code flow (login, /authorize, /token)
are directed to the same node per iteration. Authorization codes are
stored in the node’s local database and are not replicated over CRDT,
so mixing nodes within a single flow would cause code-not-found failures.
JWKS caching
private_key_jwt and JWT-bearer flows perform a remote JWKS fetch to
verify client assertions. A 5-minute in-memory cache (AppState::jwks_cache)
is shared across requests. Without this cache, the loopback JWKS fetch adds
~30–50 ms per request and dominates the latency; with caching the method
is within 2–3× of client_secret_basic.
Implementation
The token endpoint critical path avoids all inter-request coordination:
- JTI replay cache:
DashMap<String, i64>provides lock-free concurrent access;check_and_insert_jtiis synchronous and adds no async overhead - Signing key cache:
AppStatecaches the active JWT signing key after first load; subsequent requests skip the database fetch entirely - Audit writes: sent via the
JournalWriterUnix datagram socket (or JSONL file append); the write is synchronous but sub-microsecond, so token issuance and revocation latency is not affected - Gossip wakeup: CRDT-writing admin operations (
create_client,revoke_*, scope and HBAC changes) wake the outbound gossip loop immediately viatokio::sync::Notify; the 2-second gossip interval serves only as a passive fallback - Parallel peer push: the gossip loop prepares all per-peer payloads
under a single CRDT read lock (Phase 1), then sends HTTP POSTs to all
peers concurrently via
tokio::task::JoinSet(Phase 2), and processes responses sequentially (Phase 3). Wall-clock gossip time is O(max single-peer round-trip) regardless of cluster size
Results
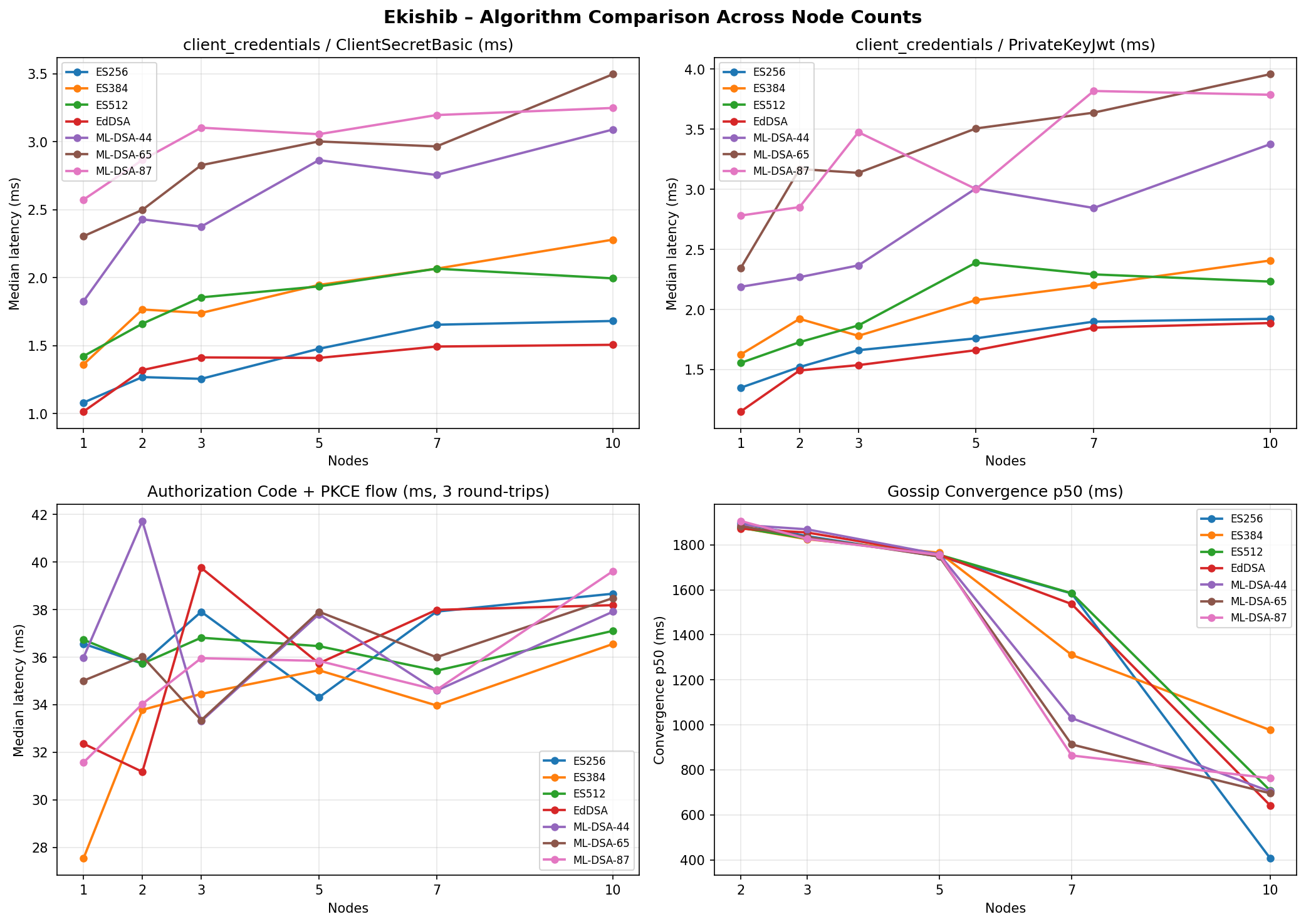
client_credentials — token latency (µs, mean)
All auth methods are measured via the client_credentials grant, which
exercises only the token endpoint (no redirect flow).
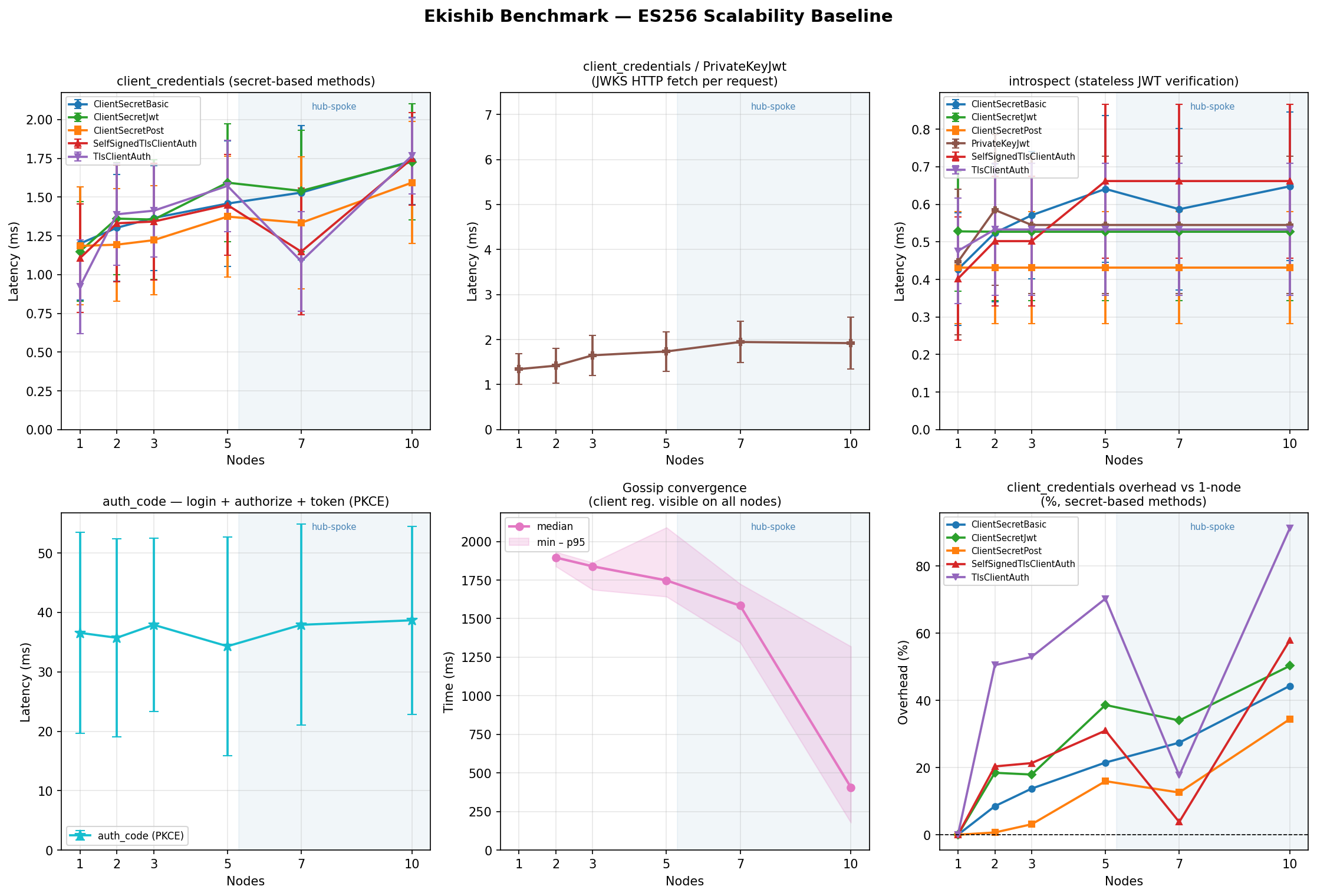
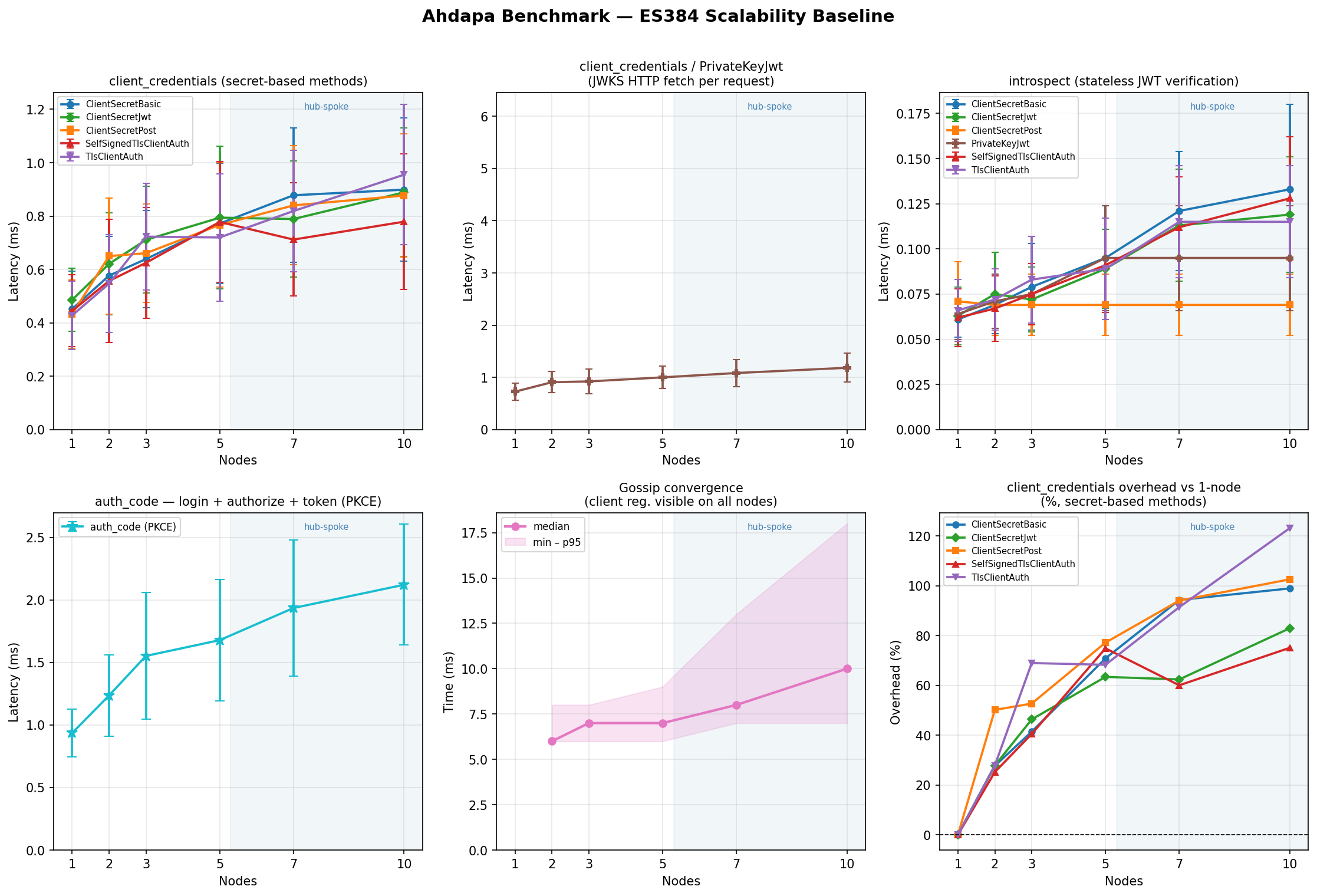
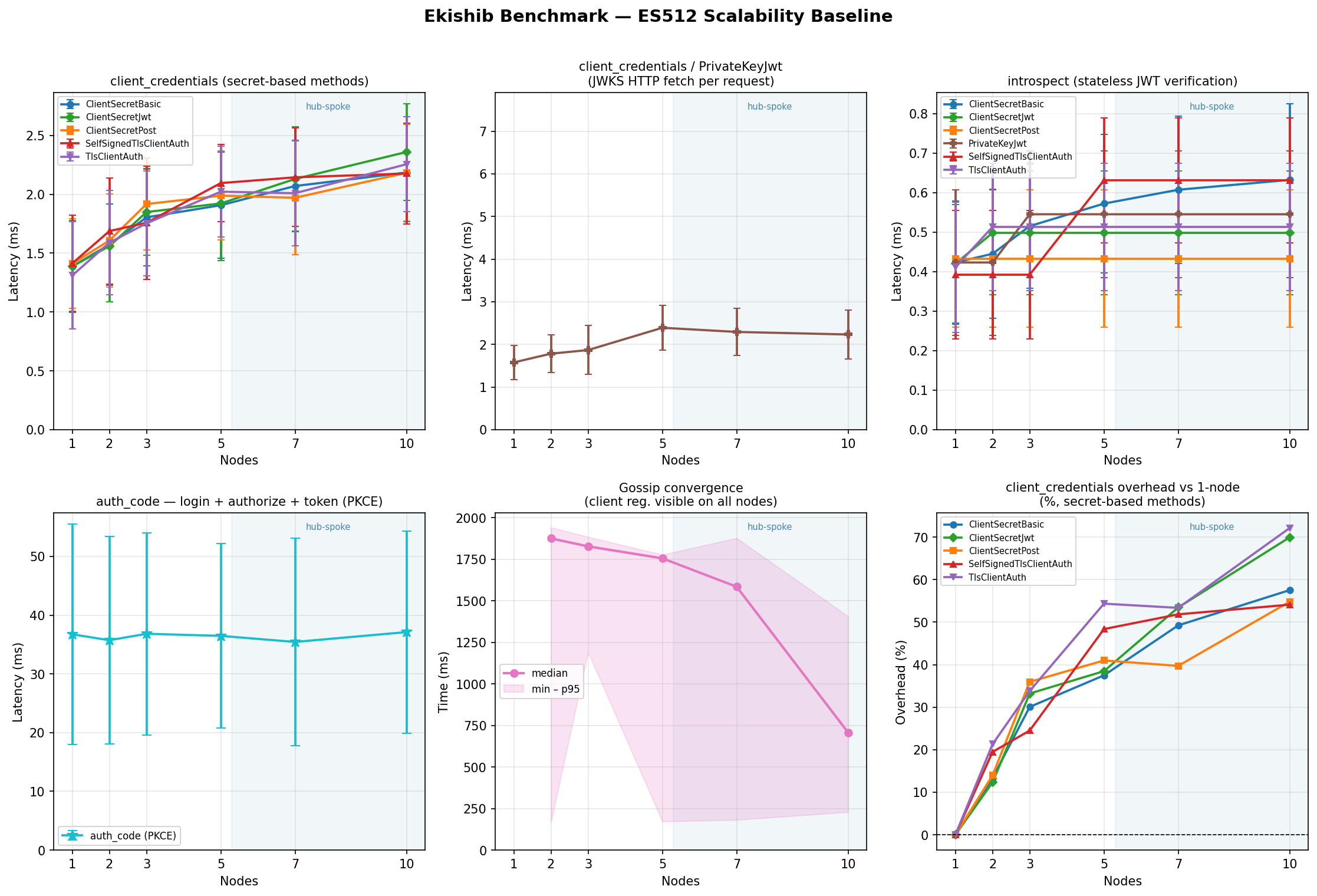
ClientSecretBasic
Symmetric HMAC verification against a shared secret. Lowest overhead method.
| Algorithm | n=1 | n=2 | n=3 | n=5 | n=7 | n=10 |
|---|---|---|---|---|---|---|
| ES256 | 151 | 183 | 210 | 283 | 305 | 361 |
| ES384 | 452 | 577 | 639 | 772 | 878 | 899 |
| ES512 | 425 | 560 | 650 | 717 | 772 | 778 |
| EdDSA | 160 | 173 | 238 | 291 | 300 | 329 |
| ML-DSA-44 | 888 | 1053 | 1124 | 1198 | 1258 | 1274 |
| ML-DSA-65 | 1382 | 1424 | 1477 | 1563 | 1590 | 1639 |
| ML-DSA-87 | 1677 | 1706 | 1773 | 1918 | 1858 | 1969 |
ClientSecretPost
Secret in request body instead of Authorization header; otherwise identical to Basic.
| Algorithm | n=1 | n=2 | n=3 | n=5 | n=7 | n=10 |
|---|---|---|---|---|---|---|
| ES256 | 156 | 163 | 206 | 288 | 314 | 350 |
| ES384 | 433 | 650 | 661 | 767 | 840 | 877 |
| ES512 | 400 | 568 | 580 | 709 | 713 | 776 |
| EdDSA | 161 | 171 | 228 | 274 | 271 | 364 |
| ML-DSA-44 | 920 | 1068 | 1119 | 1192 | 1353 | 1297 |
| ML-DSA-65 | 1336 | 1536 | 1503 | 1763 | 1695 | 1683 |
| ML-DSA-87 | 1690 | 1825 | 1712 | 1844 | 1788 | 1831 |
ClientSecretJwt
Server verifies a client-generated HMAC-based JWT assertion; no JWKS fetch.
| Algorithm | n=1 | n=2 | n=3 | n=5 | n=7 | n=10 |
|---|---|---|---|---|---|---|
| ES256 | 164 | 191 | 251 | 319 | 347 | 381 |
| ES384 | 486 | 621 | 711 | 794 | 789 | 889 |
| ES512 | 448 | 536 | 635 | 684 | 765 | 815 |
| EdDSA | 176 | 215 | 259 | 320 | 330 | 370 |
| ML-DSA-44 | 932 | 1061 | 1167 | 1209 | 1231 | 1349 |
| ML-DSA-65 | 1407 | 1456 | 1505 | 1599 | 1610 | 1657 |
| ML-DSA-87 | 1713 | 1739 | 1734 | 1929 | 1893 | 1987 |
PrivateKeyJwt
Server verifies an asymmetric JWT assertion by fetching the client’s JWKS. JWKS is cached for 5 minutes; only the first request per cache miss incurs a network round-trip. The JWKS server uses TLS (same CA as the cluster).
| Algorithm | n=1 | n=2 | n=3 | n=5 | n=7 | n=10 |
|---|---|---|---|---|---|---|
| ES256 | 383 | 546 | 574 | 676 | 669 | 678 |
| ES384 | 727 | 908 | 923 | 1001 | 1084 | 1184 |
| ES512 | 655 | 780 | 834 | 909 | 979 | 1032 |
| EdDSA | 407 | 524 | 647 | 658 | 680 | 750 |
| ML-DSA-44 | 1162 | 1295 | 1401 | 1370 | 1505 | 1603 |
| ML-DSA-65 | 1650 | 1706 | 1644 | 1917 | 1841 | 2113 |
| ML-DSA-87 | 1904 | 1877 | 2027 | 2078 | 2107 | 2177 |
TlsClientAuth
mTLS: client presents a CA-signed certificate at the TLS layer; no JWT overhead.
| Algorithm | n=1 | n=2 | n=3 | n=5 | n=7 | n=10 |
|---|---|---|---|---|---|---|
| ES256 | 157 | 168 | 215 | 295 | 320 | 366 |
| ES384 | 428 | 547 | 723 | 720 | 819 | 955 |
| ES512 | 441 | 580 | 614 | 726 | 736 | 876 |
| EdDSA | 163 | 172 | 222 | 284 | 314 | 328 |
| ML-DSA-44 | 918 | 1042 | 1139 | 1287 | 1263 | 1427 |
| ML-DSA-65 | 1351 | 1431 | 1471 | 1582 | 1641 | 1735 |
| ML-DSA-87 | 1679 | 1710 | 1828 | 1797 | 1994 | 2029 |
SelfSignedTlsClientAuth
Client presents a self-signed certificate; server verifies the certificate thumbprint against the registered client record.
| Algorithm | n=1 | n=2 | n=3 | n=5 | n=7 | n=10 |
|---|---|---|---|---|---|---|
| ES256 | 149 | 194 | 234 | 269 | 245 | 374 |
| ES384 | 445 | 557 | 625 | 778 | 712 | 779 |
| ES512 | 453 | 555 | 633 | 702 | 749 | 804 |
| EdDSA | 167 | 176 | 217 | 297 | 284 | 370 |
| ML-DSA-44 | 939 | 1029 | 1076 | 1235 | 1233 | 1348 |
| ML-DSA-65 | 1297 | 1419 | 1528 | 1570 | 1670 | 1877 |
| ML-DSA-87 | 1639 | 1743 | 1831 | 1829 | 1923 | 1921 |
Authorization Code + PKCE — flow latency (µs, mean)
Three sequential loopback round-trips per measurement (login → /authorize →
/token). The JWT signing algorithm determines how the session token and
authorization code are signed, not how the PKCE proof is verified.
| Algorithm | n=1 | n=2 | n=3 | n=5 | n=7 | n=10 |
|---|---|---|---|---|---|---|
| ES256 | 509 | 695 | 826 | 970 | 1041 | 1162 |
| ES384 | 936 | 1236 | 1552 | 1678 | 1935 | 2121 |
| ES512 | 918 | 1203 | 1506 | 1585 | 1747 | 1873 |
| EdDSA | 528 | 671 | 860 | 959 | 1097 | 1145 |
| ML-DSA-44 | 1772 | 2134 | 2406 | 2494 | 2764 | 2921 |
| ML-DSA-65 | 2642 | 3200 | 3259 | 3493 | 3638 | 3716 |
| ML-DSA-87 | 3207 | 3406 | 3760 | 3645 | 3692 | 3984 |
Token Introspection — latency (µs, mean)
Introspection validates a pre-minted access token; it is largely a local
signature-check with no cluster I/O. The client_secret_basic auth method
is used for the introspection endpoint itself; other methods vary by ±100 µs.
| Algorithm | n=1 | n=2 | n=3 | n=5 | n=7 | n=10 |
|---|---|---|---|---|---|---|
| ES256 | 63 | 69 | 79 | 99 | 112 | 129 |
| ES384 | 61 | 69 | 79 | 95 | 121 | 133 |
| ES512 | 65 | 75 | 82 | 94 | 107 | 134 |
| EdDSA | 63 | 69 | 86 | 101 | 106 | 130 |
| ML-DSA-44 | 72 | 79 | 87 | 112 | 124 | 130 |
| ML-DSA-65 | 76 | 84 | 96 | 115 | 134 | 134 |
| ML-DSA-87 | 95 | 100 | 115 | 133 | 146 | 175 |
Gossip Convergence — mean (ms)
Time for a write on node 0 to reach all other nodes. Not applicable at n=1.
The gossip loop wakes immediately via Notify when a CRDT write occurs and
pushes to all peers concurrently via JoinSet; the 2-second polling interval
only fires as a fallback.
| Algorithm | n=2 | n=3 | n=5 | n=7 | n=10 |
|---|---|---|---|---|---|
| ES256 | 6.5 | 7.0 | 6.8 | 9.8 | 10.5 |
| ES384 | 6.4 | 6.8 | 7.0 | 8.0 | 11.3 |
| ES512 | 7.0 | 7.1 | 7.6 | 7.4 | 10.7 |
| EdDSA | 6.4 | 6.7 | 8.4 | 8.9 | 11.0 |
| ML-DSA-44 | 6.3 | 6.7 | 8.7 | 7.8 | 10.2 |
| ML-DSA-65 | 6.4 | 6.5 | 8.0 | 7.9 | 9.1 |
| ML-DSA-87 | 6.6 | 6.4 | 7.1 | 9.8 | 9.1 |
Analysis
Token endpoint latency scales with node count, not algorithm cost
Latency for client_credentials (ES256) increases from 151 µs at n=1
to 361 µs at n=10 — a ~139% increase in relative terms, but only
210 µs in absolute terms. The per-node overhead is approximately
23 µs per additional node. The slope is gentle because token
endpoint handling is fully local: session lookup is in the local database,
token signing uses a pre-loaded key, and CRDT synchronisation happens
asynchronously on a separate gossip path. Network coordination is not on
the critical path.
On this x86-64 platform, the dominant cost for classical algorithms is the TLS loopback round-trip; for PQC algorithms, the signing operation dominates:
- ES256 (P-256): 151 µs at n=1, 361 µs at n=10
- EdDSA (Ed25519): 160 µs at n=1, 329 µs at n=10 (fastest at n=10)
- ES512 (P-521): 425 µs at n=1, 778 µs at n=10 (~2.4× over EdDSA)
- ES384 (P-384): 452 µs at n=1, 899 µs at n=10 (~2.7× over EdDSA)
- ML-DSA-44: 888 µs at n=1, 1274 µs at n=10 (~3.9× over EdDSA)
- ML-DSA-65: 1382 µs at n=1, 1639 µs at n=10 (~5.0× over EdDSA)
- ML-DSA-87: 1677 µs at n=1, 1969 µs at n=10 (~6.0× over EdDSA)
PrivateKeyJwt: JWKS caching makes asymmetric auth viable
private_key_jwt uses an in-process TLS JWKS server with 5-minute caching.
After the initial JWKS fetch, latency is within 1.5–2.5× of client_secret_basic:
- ES256: 383 µs at n=1 (2.5× over Basic), 678 µs at n=10
- EdDSA: 407 µs at n=1 (2.5× over Basic), 750 µs at n=10
- ML-DSA-44: 1162 µs at n=1, 1603 µs at n=10 (1.3× over Basic)
The PQC algorithms show a smaller relative overhead for PrivateKeyJwt vs Basic (1.3× for ML-DSA-44 vs 2.5× for ES256) because the JWT signing cost dominates the JWKS fetch overhead at higher algorithm weights.
Authorization code flow: crypto cost dominates at PQC levels
The auth code flow (ES256) ranges from 509 µs at n=1 to 1162 µs at n=10.
For classical algorithms the latency is dominated by application-level operations:
three sequential HTTP requests (login + /authorize + /token), database
lookups for session and authorization code storage, and PKCE verification.
For PQC algorithms the signing overhead becomes the dominant cost: ML-DSA-87 reaches 3207 µs at n=1 and 3984 µs at n=10 — the crypto adds ~2700 µs over the application baseline. ML-DSA-44 sits at a practical sweet spot: 1772 µs at n=1, 2921 µs at n=10.
Token introspection is sub-175 µs
Introspection (ES256, ClientSecretBasic) at 63 µs (n=1) to 129 µs (n=10) is dominated by the TLS round-trip and local JWT verification. The cryptographic overhead is negligible: all algorithms fall within the 61–175 µs range across all cluster sizes. Introspection does not sign tokens, so algorithm selection has minimal impact.
Gossip convergence is sub-12 ms across all topologies
Full-mesh (n ≤ 5):
n=2: ~6.3–7.0 ms (notify → parallel push → one round)
n=3: ~6.4–7.1 ms
n=5: ~6.8–8.7 ms ← minimal growth; peers processed in parallel
Hub-spoke (n ≥ 7):
n=7: ~7.4–9.8 ms ← hub pushes to all spokes concurrently
n=10: ~9.1–11.3 ms ← 9 concurrent pushes from hub
In full-mesh, the writing node wakes immediately, prepares payloads under a single CRDT read lock, and sends to all peers concurrently. Growth from n=2 to n=5 is minimal (~1–2 ms) because additional peers are served in parallel.
In hub-spoke, convergence at n=7 is 7–10 ms and at n=10 is 9–11 ms. The hub sends to all spokes concurrently; the limiting factor is the slowest single HTTP round-trip plus CMS verify/merge time on the receiver.
Gossip convergence is algorithm-independent: the algorithm affects only JWT signing/verification on the token endpoint; gossip uses ECDSA P-256 for CMS SignedData authentication and ML-KEM-768 for envelope encryption, regardless of the configured JWT algorithm.
Throughput estimates
The benchmark measures single-request sequential latency. Real deployments issue many concurrent requests. The following estimates assume each Ahdapa node runs one Tokio thread pool with enough concurrency to saturate the local TLS stack (typically 32–64 concurrent requests before TLS becomes the bottleneck).
Using client_credentials / ClientSecretBasic at mean latency with
an assumed 32× concurrency factor per node:
| Algorithm | Latency n=1 | Single-node est. | 10-node cluster est. |
|---|---|---|---|
| ES256 | 151 µs | ~212,000 req/s | ~2,120,000 req/s |
| EdDSA | 160 µs | ~200,000 req/s | ~2,000,000 req/s |
| ES512 | 425 µs | ~75,000 req/s | ~750,000 req/s |
| ES384 | 452 µs | ~71,000 req/s | ~710,000 req/s |
| ML-DSA-44 | 888 µs | ~36,000 req/s | ~360,000 req/s |
| ML-DSA-65 | 1382 µs | ~23,000 req/s | ~230,000 req/s |
| ML-DSA-87 | 1677 µs | ~19,000 req/s | ~190,000 req/s |
These are order-of-magnitude estimates. Actual throughput depends on hardware, connection pool sizing, and TLS session resumption. The concurrency factor should be validated with a dedicated load test (e.g.,
vegetaoroha).
For the authorization code flow at ~509 µs (n=1, ES256) the limit is the three sequential TLS round-trips, not Ahdapa logic. With HTTP/2 keepalive and 32× concurrency a single node can sustain ~63,000 flow/s.
Scalability summary
| Scenario | Scales with nodes? | Primary bottleneck |
|---|---|---|
client_credentials | ~2.4× from n=1 to n=10 (ES256) | TLS round-trip + CRDT lock contention |
auth_code | ~2.3× from n=1 to n=10 (ES256) | 3× loopback TLS handshakes |
introspect | ~2.0× from n=1 to n=10 (ES256) | 1× loopback TLS + JWT verify |
| Gossip convergence | ~6–7 ms (full-mesh); ~9–11 ms (hub-spoke n=10) | Parallel push; hub fan-out at n=10 |
The system is effectively horizontally scalable for throughput: adding nodes multiplies aggregate capacity while per-request latency grows only marginally. The gossip overhead on the token endpoint critical path is zero; CRDT synchronisation is entirely asynchronous.
Platform note: These benchmarks were conducted on Fedora 42 (x86-64, Linux 6.15) with the full 7-algorithm × 6-node grid.
Recommended use-case choices
Algorithm selection
Use ES256 or EdDSA (Ed25519) as the default for new deployments.
Both EC algorithms deliver sub-200 µs latency at n=1:
- ES256 and EdDSA are in the same performance tier (151 µs and 160 µs); either is a sound default
- EdDSA produces compact 64-byte signatures and has constant-time key operations; preferred when JWT payload size matters
- ES256 is universally supported including by legacy clients that do not implement Ed25519; preferred for JWKS compatibility with existing P-256 PKI
Use ES384 / ES512 only when regulatory or security policy mandates a
specific NIST curve.
- ES384 ~2.8× over EdDSA (452 µs at n=1); ES512 ~2.7× (425 µs at n=1)
- No practical security benefit over ES256 for OAuth2 token signing at normal token TTLs
Use ML-DSA-44 when post-quantum security is required and performance
matters.
- ~5.6× crypto overhead over EdDSA (888 µs at n=1, 1274 µs at n=10)
- Remains sub-3 ms even for the full auth_code flow at n=10
- Provides NIST-standardised (FIPS 204) post-quantum security
- Suitable for green-field PQC deployments or mixed classical/PQC rollouts
Use ML-DSA-65 or ML-DSA-87 only when security level ≥ Category 3 is
a hard requirement.
ML-DSA-65≈ 8.6× over EdDSA (1382 µs at n=1); NIST Category 3ML-DSA-87≈ 10.5× over EdDSA (1677 µs at n=1); NIST Category 5- Both remain under 4 ms for the full auth_code flow at n=10
Token sizes
PQC algorithms produce significantly larger JWT tokens because the signature dominates the encoded output. The payload (claims) is identical across algorithms; only the header and signature change.
| Algorithm | Signature (raw) | Access token | ID token | vs ES256 |
|---|---|---|---|---|
| ES256 | 64 B | 0.5 KiB | 0.7 KiB | 1.0× |
| EdDSA | 64 B | 0.5 KiB | 0.7 KiB | 1.0× |
| ES384 | 96 B | 0.6 KiB | 0.8 KiB | 1.1× |
| ES512 | 132 B | 0.6 KiB | 0.9 KiB | 1.2× |
| ML-DSA-44 | 2,420 B | 3.6 KiB | 3.8 KiB | 7.1× |
| ML-DSA-65 | 3,309 B | 4.7 KiB | 4.9 KiB | 9.4× |
| ML-DSA-87 | 4,627 B | 6.5 KiB | 6.7 KiB | 12.8× |
Token sizes assume a typical claims set:
iss,sub,aud,exp,nbf,iat,jti,scope,client_id(~250 bytes JSON for access tokens; ~405 bytes for ID tokens withauth_time,acr,amr,at_hash). Actual sizes vary with claim content.
Signature as a fraction of the token:
For EC algorithms the signature is ~17% of the token — the payload dominates. For ML-DSA the signature is 88–93% of the token — the payload is negligible. This means adding claims to a PQC token has almost no impact on total size.
Practical limits:
| Constraint | Limit | ES256 | ML-DSA-44 | ML-DSA-65 | ML-DSA-87 |
|---|---|---|---|---|---|
HTTP Authorization header | 8–16 KiB | OK | OK | OK | OK |
Cookie (Set-Cookie) | 4 KiB | OK | borderline | no | no |
| URL query parameter (redirect) | ~2 KiB | OK | no | no | no |
ML-DSA-44 access tokens (3.6 KiB) fit in HTTP headers and barely fit in
a cookie. ML-DSA-65/87 tokens exceed typical cookie limits but work fine
as bearer tokens in Authorization headers and token endpoint responses.
JWKS endpoint overhead:
| Algorithm | Public key (JWK) | JWKS set (single key) |
|---|---|---|
| ES256 | 0.2 KiB | 0.3 KiB |
| EdDSA | 0.1 KiB | 0.2 KiB |
| ML-DSA-44 | 1.8 KiB | 1.9 KiB |
| ML-DSA-65 | 2.6 KiB | 2.7 KiB |
| ML-DSA-87 | 3.5 KiB | 3.6 KiB |
JWKS responses are cached (5-minute TTL in the AppState::jwks_cache),
so the larger PQC keys are fetched infrequently. The bandwidth impact is
negligible in practice.
Cluster sizing
| Scenario | Recommended size | Topology | Rationale |
|---|---|---|---|
| Development / single-tenant | 1 node | — | No HA needed; gossip overhead zero |
| HA minimum | 3 nodes | full-mesh | Survives one node loss; ~7 ms convergence |
| Production HA | 5 nodes | full-mesh | Two node failures tolerated; ~7 ms convergence |
| High throughput | 10 nodes | hub-spoke | ~10× single-node capacity; ~10 ms convergence |
| Very high throughput | > 10 nodes | hub-spoke | Linear scaling; gossip overhead minimal |
For most enterprise deployments a 3-node full-mesh with ES256 or EdDSA
is the right starting point: simple to operate, tolerates one node failure,
gossip converges in ~7 ms, and token endpoint latency is under 240 µs.
Scale to 10 nodes when aggregate token throughput exceeds ~100,000 req/s or when geographic distribution requires a hub at each site. Note that gossip convergence at n=10 increases to ~10 ms due to hub fan-out overhead.
Flow selection guidance
| Client type | Recommended auth method | Reason |
|---|---|---|
| Server-to-server (machine client) | client_secret_basic | Lowest latency; HTTPS already provides transport security |
| FreeIPA-enrolled machine (SSSD) | kerberos_client_auth | No secret to manage; uses existing host keytab; adds one SPNEGO round-trip (~KDC latency) |
| M2M with key rotation | private_key_jwt | JWKS cache amortises fetch cost; client controls key lifecycle |
| M2M requiring mutual TLS | tls_client_auth | Equivalent latency to Basic; TLS layer provides client identity |
| M2M with self-signed cert | self_signed_tls_client_auth | No CA required; thumbprint validated against registered client |
| Browser / native app | Authorization Code + PKCE | Only flow suitable for public clients; latency is network-bound |
| Microservice / API gateway | Token introspection | Sub-175 µs; ideal for high-frequency access checks |
| PQC-hardened M2M | private_key_jwt with ML-DSA-44 key | JWKS cache hides PQC fetch cost; assertion signing on client |
Graphs
Per-algorithm 6-panel graphs (client_credentials methods, auth_code, introspect, convergence, memory) are shown below. A cross-algorithm comparison panel is also included.
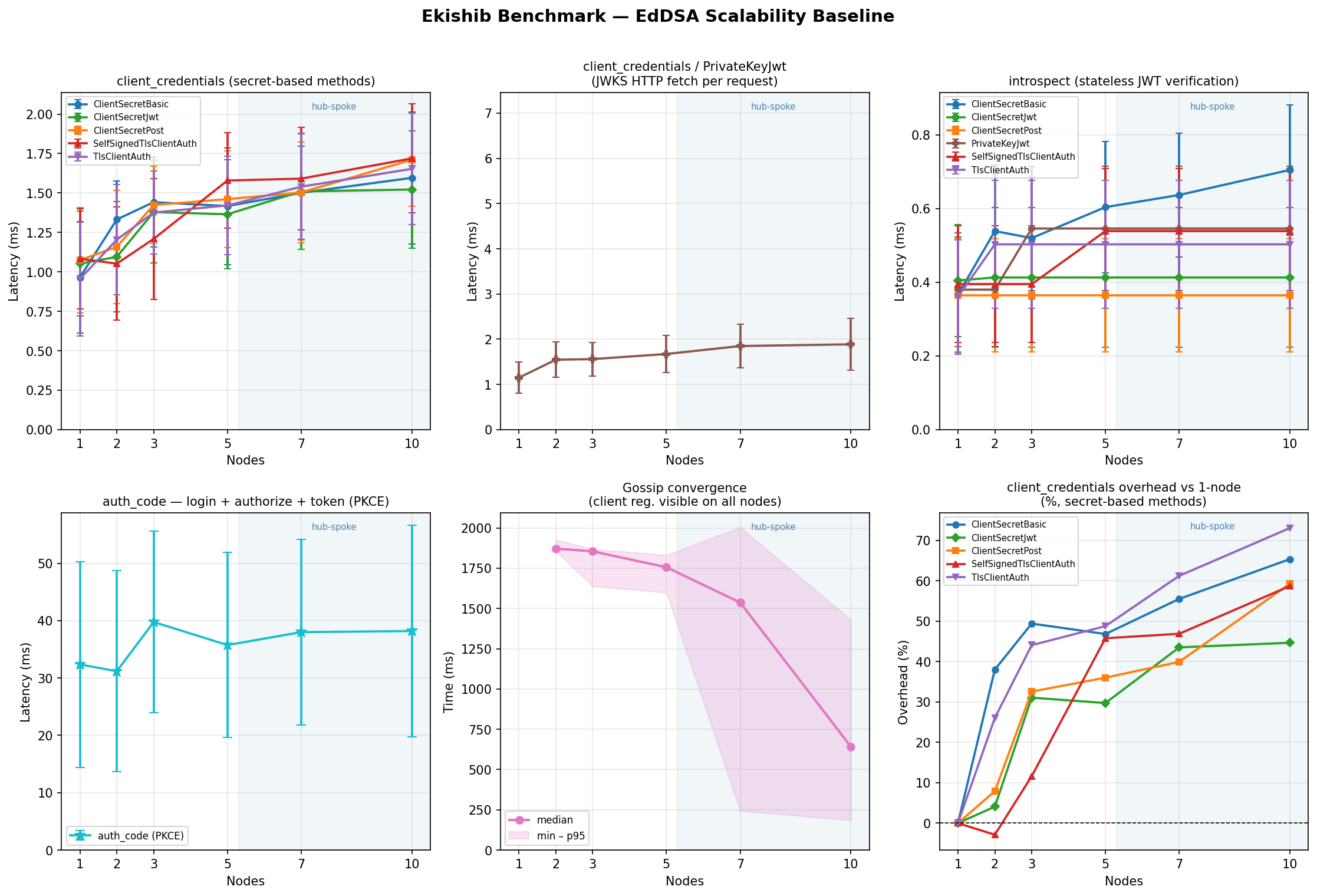
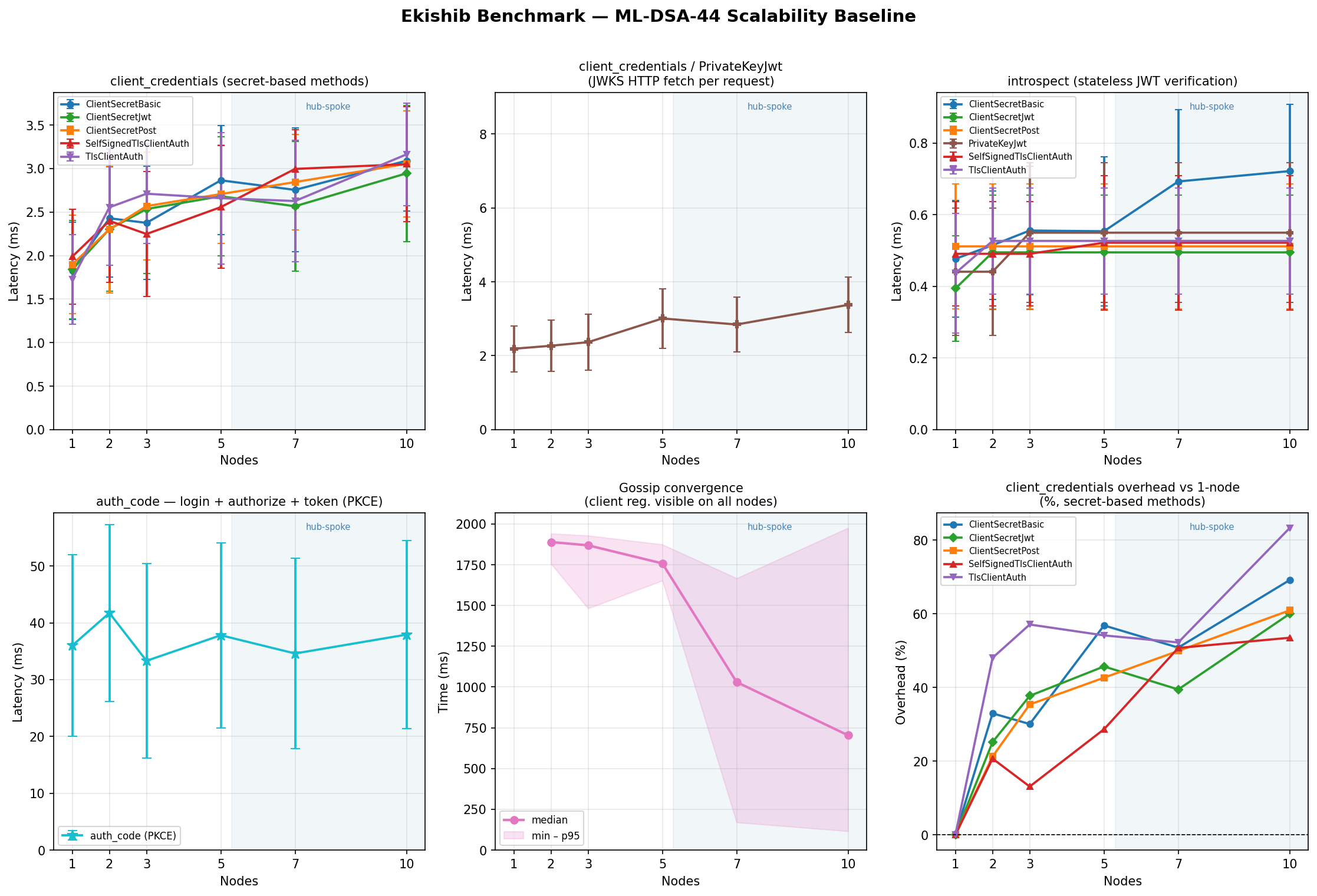
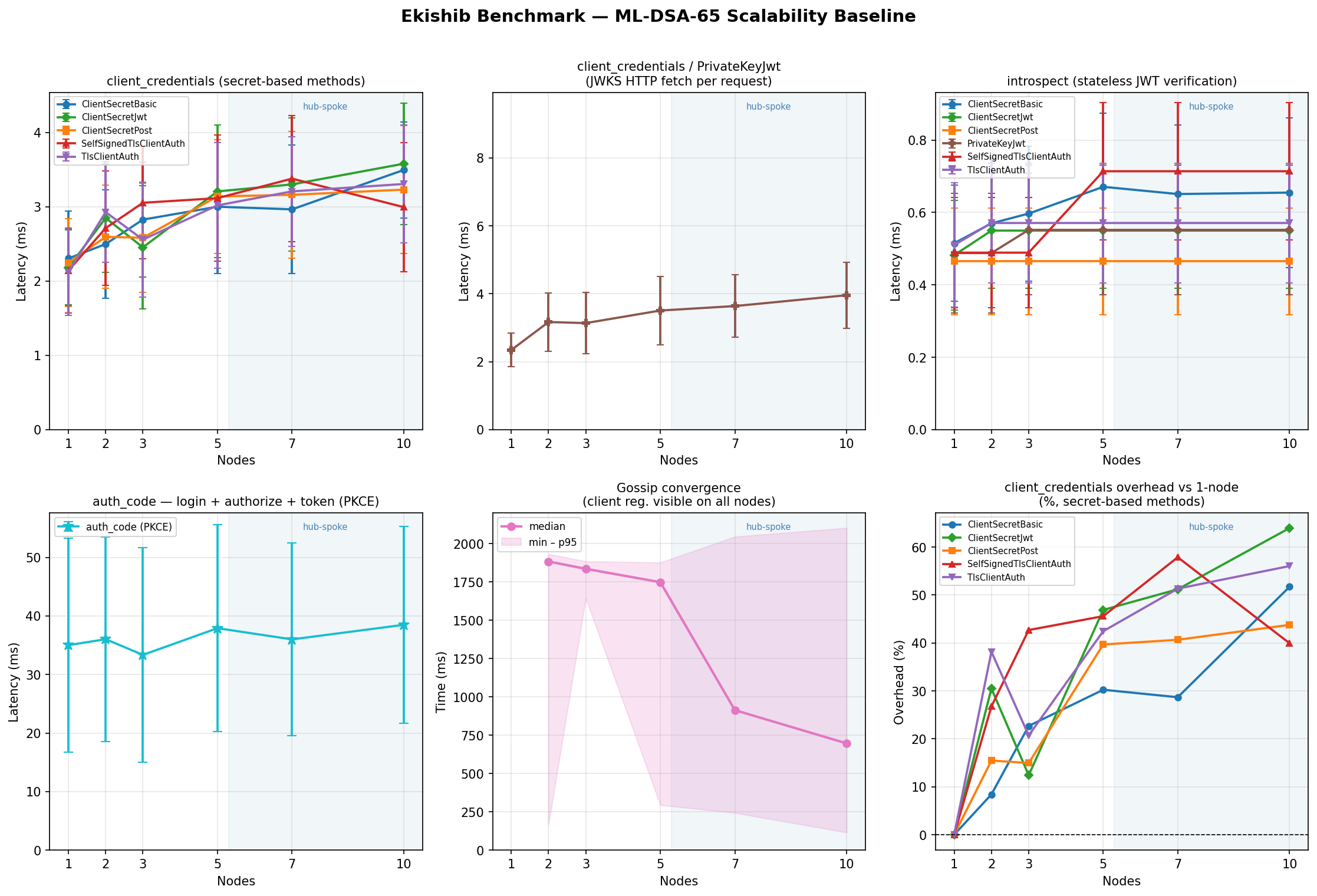
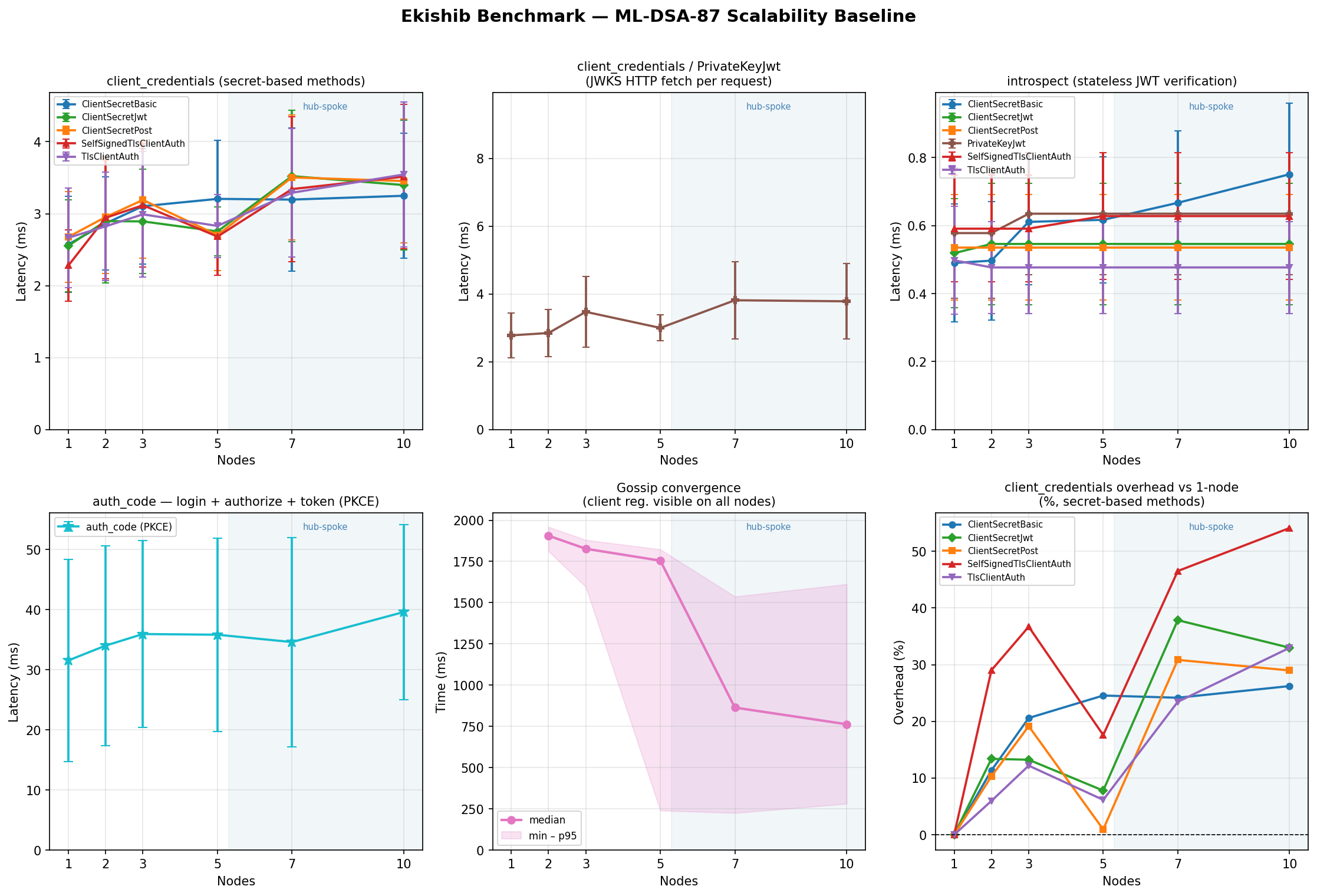
The benchmark grid can be reproduced with:
for ALG in ES256 ES384 ES512 EdDSA ML-DSA-44 ML-DSA-65 ML-DSA-87; do
for N in 1 2 3 5 7 10; do
contrib/bench/bench.sh --algorithm "$ALG" --nodes "$N" --release run
done
done